📘 논문: Interoperability in Deep Learning: A User Survey and Failure Analysis of ONNX Model Converters
📅 발표: ISSTA 2024, Vienna
🧠 주제: 딥러닝 모델 변환기(ONNX)의 실패 원인 분석 및 사용자 경험 조사
요약: 모델 구조에 따라 성능저하/변환실패가 야기될 수 있다.
- 주로 모델 배포와 프레임워크간 변환을 위해 ONNX를 사용함
- 주로 모델변환실패(충돌), 성능 저하 가 대부분 이슈
- ONNX변환기는 아직 개발 중으로, 테스트 커버리지가 충분하지 않음
- 대부분 node conversion에서 문제 발생하며, 연산자 미지원/시멘티 불일치/데이터 타입불일치 /파라미터 누락 등으로 발생함
- node conversion: 딥러닝 모델을 ONNX 포맷으로 바꾸는 과정에서, 각 연산자 노드(operator node) 를 ONNX의 대응 연산자로 매핑하는 단계 (PyTorch의 torch.max() → ONNX에서는 ReduceMax + ArgMax로 분해)
1. Introduction (소개)
핵심 내용:
- 다양한 프레임워크와 런타임 환경에서 DL 모델을 개발, 재사용, 배포함.
- ONNX는 대표적인 딥러닝 모델 변환 표준이지만, 변환 오류는 예측하기 어렵고 심각한 문제를 유발함.
- 92명의 엔지니어 대상 설문과 200개의 GitHub 이슈 분석을 통해 문제의 원인과 특성을 파악함.

설명:
- 모델은 개발 후 변환(A), 컴파일(B), 배포(C), 다른 프레임워크로 전환(D)됨.
- ONNX는 중간 표현(IR)로써 이 과정을 간소화하는 역할을 함.
2. Background and Related Work (배경 및 관련 연구)
핵심 내용:
- DL 모델 변환기는 컴파일러 프론트엔드처럼 작동.
- ONNX는 공통 표현을 제공하는 대표적인 인터페이스.
- 기존 연구는 개발 프레임워크나 컴파일러의 오류를 다뤘고, 모델 변환기의 실패에 대한 연구는 미비함.
표 1: ONNX 모델 변환기의 구성 단계
구성 단계설명
| LoadModel | 프레임워크 → ONNX 그래프 |
| Node Conversion | 노드를 ONNX 연산자로 변환 |
| Optimization | 노드 및 데이터 흐름 최적화 |
| Export | protobuf로 직렬화 |
| Validate | 문법 및 의미 검사 |
설명:
- PyTorch의 torch.max는 ONNX에선 ArgMax + ReduceMax 조합으로 변환됨.
3. Research Questions & Study Design (연구 질문과 설계)
- RQ1: 사용자 경험 (설문조사)
- RQ2: ONNX 변환기의 실패 증상, 원인, 위치
- RQ3: ONNX 스펙 변화와 실패율의 상관성
- RQ4: 모델 구조와 실패율의 관계
4. Theme 1: 사용자 설문조사 (RQ1)
표 2: 설문 문항 예시
주제예시 문항
| Interoperability 사용 경험 | ONNX를 어떤 목적으로 사용합니까? |
| 실패 경험 | ONNX 사용 중 어떤 문제를 겪었나요? |
표 3: 응답자 통계
구분분포
| ML 경력 | >5년: 32명 |
| SE 경력 | >5년: 53명 |
| 사용 환경 | 웹 앱: 59명, 클라우드: 52명 |
주요 결과:
- ONNX 사용자가 가장 많았으며, 주요 용도는 모델 배포와 프레임워크 간 변환.
- 문제 발생율은 59%, 주로 **충돌(Crash)**과 성능 저하.
5. Theme 2: 실패 분석 (RQ2)
표 8: 실패 발생 위치
위치비율
| Node Conversion | 74% |
| Optimization | 10% |
| LoadModel | 6% |
표 9: 실패 증상
증상비율
| Crash | 56% |
| Wrong Model | 33% |
| Bad Performance | 2% |
표 10: 주요 원인과 증상
- Crash: Incompatibility와 Type Problem
- Wrong Model: Algorithmic Error, Type Problem
6. Theme 3: 원인 분석 (RQ3, RQ4)
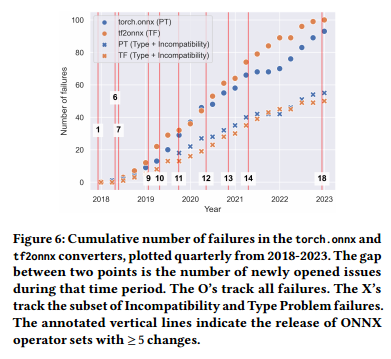
결론 (RQ3):
- ONNX 연산자 세트 변화는 변환 실패와 직접적인 상관성이 없음.
RQ4: 모델 구조가 실패율에 영향을 주는가?
표 11: 모델별 실패율
구분Real 모델Synthetic 모델
| 변환 실패 | 2–4% | 최대 44% |
| ORT 로딩 실패 | ~2% | 42% |
| 결과 불일치 | 1% | 6–12% |
표 12: 오퍼레이터 시퀀스 공유 분석
구분tf2onnxtorch.onnx
| 실패 모델 내 시퀀스 공유 | 2,125 | 980 |
| 실패 ↔ 성공 모델 공유 | 1,050 | 4,243 |
| 실패 ↔ 테스트 모델 공유 | 35 | 2 |
결론 (RQ4):
- 개별 연산자보다 연산자 시퀀스가 실패를 더 잘 설명.
- 기존 테스트 세트는 실패 모델과 공유 구조가 거의 없음 → 테스트 커버리지 부족.
✅ 결론
- Node Conversion 단계가 가장 많은 문제의 원인 (약 75%)
- ONNX 연산자 변경 자체보다는, 모델 구조(특히 연산자 시퀀스)가 변환 실패의 주요 원인
- 실모델보다는 합성(Synthetic) 모델에서 오류가 자주 발생
- 테스트 세트 개선 필요: 연산자 시퀀스 커버리지 확대가 필요함
📂 원문 논문 & 실험 데이터
반응형