목차
0. Abstract
고성능 비전 트렌스포머를 이미지 이해 작업 처리하는데 사용함
86M 파라미터를 이용하여 ImageNet에서 top-1 accuracy를 83.1% 달성
1. Introduction
- Convolution 신경망 ( Imagenet)
- Natural Language Processing에서 attention-based models 활용
- 최근에는 여러 연구자가 비전과제를 해결하기위해 hybrid architecture를 사용하는데, transformer 성분을 Conv-Net에 적용
ex) The vision transformer (ViT) introduced by Dosovitskiy et al. - Natural Language Processing (Vaswani et al., 2017)에서 유래함
> 3억 개의 이미지가 포함된 대규모 비공개 레이블링 이미지 데이터 세트로 훈련된 변압기로 우수한 결과를 제시
> 하지만, vision transformer에서는 데이터 셋이 적으면 잘 일반화 되지 않는다고함
In this paper
- single 8- GPU node에서 2~3일 사전교육, 미세조정하여 훈련한다
- Data-efficient image Transformers (DeiT): Dosovitskiy et al. (2020)의 visual transformer architecture와 timm library (Wightman, 2019)를 이용함
* timm library

1) Conv 없이, 외부 데이터 없이 ImageNet의 최신 기술에 대해서 좋은 성능을 보여줌
- 3일동안, 4개의 GPU를 이용해서 학습
- DeiT-S와 DeiT-Ti는 매개 변수가 적으며 ResNet-50과 ResNet-18의 대응물
2) 새로운 distillation procedure based on a distillation token를 제안
- class token과 동일한 역할을 하지만, 교사가 추정하는 라벨을 재현하는 것을 목표로 한다는것
( e.g. random crop & resize해서 cat? hard label, soft label)
- class와 distillation token의 경운 transformer에서 상호작용함. vanilla distillation에서 상당한 차이 존재
3) 오픈 퍼블릭 벤치마크에 downstream tasks으로 작업할 때 이득이 있음
- CIFAR-10, CIFAR-100, Oxford-102 flowers, Stanford Cars and iNaturalist-18/19.
* downstream tasks
2. Related work
1) Image Classification
- AlexNet이 표준이 되었음, ImageNet 데이터 세트에 대한 최첨단 기술의 발전(Russakovsky et al., 2015)은 컨볼루션 아키텍처와 최적화 방법의 진전을 반영
- 이미지 분류를 위해 변압기를 사용하려는 여러 시도에도 불구하고(Chen 등, 2020a), 지금까지 그 성능은 컨넷의 성능보다 떨어졌다
- 그럼에도 불구하고 자기 주의 메커니즘을 포함한 컨넷과 변압기를 결합한 하이브리드 아키텍처는 이미지 분류(Bello et al., 2019; Bello, 2021; Wu et al., 2020), 감지(Carion et al., 2020; Hu et al, 2018), 비디오 처리(Sun et al., 2019; Wang, 2018)에서 경쟁적인 결과
- 비전 트랜스포머(ViT)(Dosovitski et al., 2020)는 컨볼루션 없이 ImageNet의 최신 기술과의 격차를 좁혔음
> 하지만, trained transformer가 좋은 성능을 보이려면, 대량의 큐레이션된 데이터에 대한 사전 훈련단계가 필요
*큐레이션
- ImageNet-1k로 강력한 성능을 달성하고 CIFAR-10에서도 괜찮은 결과를 보고
2) The Transformer architecture
- transformer architecture는 모든 자연어 처리 작업의 참조모델
- 이미지 분류를 위한 Conv-net의 많은 개선을 통해 transformer 구조에 영향을 미침
> Squeeze and Excitation (Hu et al., 2017), Selective Kernel (Li et al., 2019b), Split-Attention Networks (Zhang et al., 2020) and Stand-Alone Self-Attention (Ramachandran et al., 2019) exploit mechanism akin to transformers self-attention (SA) mechanism. Moreover, Cordonnier et al. (Cordonnier et al., 2020) study the link between SA and convolution.
3) Knowledge Distillation
* Knowledge distillation 의 목적은 "미리 잘 학습된 큰 네트워크(Teacher network) 의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network) 에게 전달하는 것 ( https://light-tree.tistory.com/196)
- 그냥 점수를 토대로 나오는 값이 아닌, 선생님이 도출한 softmax인 것 >> 따라서 학습 성능이 향상됨
- convolutional bias into transformers를 이용한 Conv-net이나, transformer teacher의 transformer student를 연구함
3. Vision transformer: overview
- ViT에 대하여
1) Multi-head Self Attention layers (MSA)
2) Transformer block for images.
3) The class token
4) Fixing the positional encoding across resolutions.
4. Distillation through attention
LCE: cross-entropy / y: ground truth labels / ψ the softmax function
Soft distillation ( hard 와 비교?)
- teacher의 softmax와 student 모델의 softmax의 Kullback-Leibler divergence 차이를 해결
Hard-label distillation.
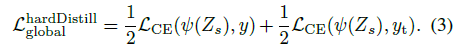
Label smoothing.
- 하드 레이블은 소프트레이블로 변환가능
- 실제 레이블은 1-a의 확률을 가지고, 나머지 a는 나머지 클래스에 걸쳐 공유 ( a= 0.1고정)
- teacher가 제공하는 레이블을 매끄럽게 하지는 않음
Distillation token.
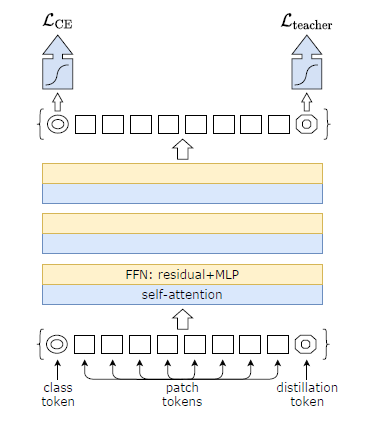
Fine-tuning with distillation.
- 실제 레이블과 teacher 예측을 모두 사용
- 낮은 해상도 teacher로 부터 얻은 동일한 목표 해상도의 teacher로 사용함
- truth label로 테스트 했ㅇ르때, teacher의 cost를 감소 시키고, 성과가 낮아짐
Classification with our approach: joint classifiers.
- 테스트 시, transformer의해 생성된 클래스 또는 증류 임베딩 모두 선형 분류기와 연결되어 이미지 레이블을 유추 가능
- 우리의 참조 방법은 이 두 개의 분리된 헤드의 늦은 융합이며, 이를 위해 두 분류기에 의한 소프트맥스 출력을 추가하여 예측한다. 우리는 섹션 5에서 이 세 가지 옵션을 평가한다.
5. Experiments
5.1. Transformer models
- Dosovitskiy et al. (2020)의 conv 없는 모델과 동일.
- training strategies과, distillation token만 다름
5.2. Distillation